
3장. 메모리
메모리는 개념적으로는 단순한데, 0과 1을 저장할 수 있는 사물함에 불과합니다.
다만 그 0과 1을 저장할 수 있는 사물함의 칸이 어마어마하게 많고, 컴퓨터가 사용하기 쉽게 설계되어 있을 뿐입니다.
우리의 컴퓨터는 0과 1 메모리 셀 하나만으로 메모리를 관리하기 보다는 8개의 0과 1(bit)를 모아서 byte 단위로 사용합니다.
8bit =1 byte 인 셈이죠.
이 바이트 마다 번호를 붙이고 이 번호(주소)를 일반적으로 메모리 주소 라고 합니다.
이러한 메모리 주소에 직접적으로 load, store를 할 수도 있겠지만 메모리 주소를 가르키는 것으로 우리는 프로그램을 짜지 않습니다.
메모리에 값을 담기 위해서 우리는 변수를 사용합니다.
또한 메모리 주소를 더 높은 수준으로 추상화 하기 위한 ‘포인터’라는 개념을 만들어 사용합니다.
포인터는 메모리 주소를 represent하는 변수 인 것이죠.
포인터를 이용해서 우리는 메모리 주소를 직접적으로 사용할 수 있게 되었지만, 반대급부로 부작용도 있습니다.
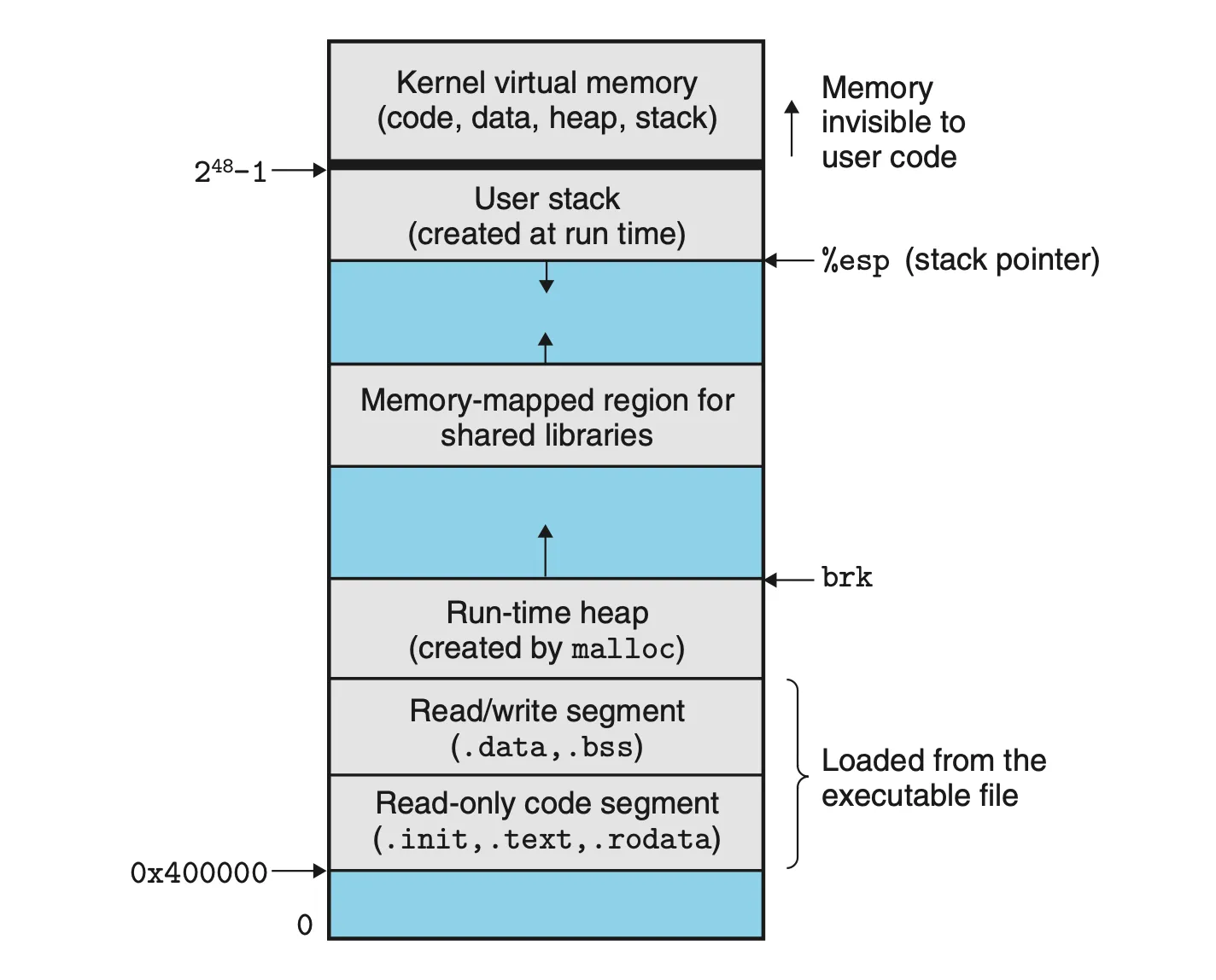
위의 사진처럼 프로세스가 실행될 때 메모리가 매핑됩니다.
c언어에서 malloc을 하게 되면 여러 과정들을 거쳐 heap에 메모리가 할당이 되는데, 해당 메모리를 해제하지 않고 사용을 한다던가,
buffer overflow의 문제가 발생한다던가.. 하는 여러가지 문제가 발생할 수 있어 포인터를 다룰 때에는 항상 조심해야 합니다.
가상 메모리, Page Table
한편, 위의 메모리 내 프로세스 구조는 실제 우리의 컴퓨터에 저렇게 할당되어 있지는 않습니다.
메모리는 작은 page로 나뉘어서 해당 page가 실제 physical memory에 할당이 되는 것 입니다.
그래서, user space에서는 내가 실제로 어느 physical memory에 할당이 되었는지 알 수 있는 방법이 없습니다.
다만, virtual memory 주소를 알 뿐입니다.
그러면 해당 virtual memory <-> physical memory간의 매핑 관계가 있다는 것인데, 이것을 다루는 것이 page table입니다.
page table을 사용하면서 운영체제 수업을 들었던 것이 자연스럽게 기억이 났는데,
demand paging, page fault, page-replacement algorithm같은 부분들은 책에서 다루지는 않았습니다.
이 책의 독자가 책을 읽고 나서 더 관심이 있다면 MMU(Memory Management Unit)나 TLB(Translation Look-aside Buffer), Multi-level page table 정도는 추가로 더 공부하면 좋을 것 같습니다.
메모리 자체를 할당하고 해제하는 과정에 있어서 효율적으로 하는 방법에 대한 알고리즘 몇개를 소개시켜주었는데,
메모리 조각의 머리와 끝에 조각 크기에 대한 정보를 추가로 할당하여 일종의 doubly linked list로 활용하여 구현 한 아이디어가 재미있었습니다.
현재 리눅스 커널 기준으로는 크기에 따라 다른 할당자를 사용합니다.
SLUB Allocator (Small Objects)
- 작은 메모리(페이지보다 작은 바이트 단위)에 대해서는 2^n 단위로 (8, 16, 32, 64, …) slab을 사용하고, 큰 메모리에 대해서는 alloc_pages를 호출
- 메모리 블록을 재활용하여 성능을 높이는 것을 목표로 SLUB 할당자(SLUB Allocator)를 사용
Buddy Allocator (Page-level)
- 페이지들은 2의 제곱 크기인 블럭으로 할당됩니다.
- 내부적으로 11개의 Zone을 가지고 있으며, 연속된 page의 개수를 가지고 정렬합니다.
SLUB 할당자는 작은 메모리를 수시로 할당하는 경우(inode, socket)등의 경우를 위해서 continuous한 공간을 미리 할당을 해 두는 느낌이고,
Buddy 할당자는 큰 메모리를 할당할 때에 page단위로 할당하여 용이하게 하기 위한 느낌입니다.
이외에 page swap 알고리즘, 동적 플레그 기반 할당 등 메모리와 관련된 많은 알고리즘이 있습니다.
Stack과 Heap
함수 호출를 일종의 퀘스트로 비유했습니다.
어떤 퀘스트는 연계 퀘스트가 있어서 기존 메인 퀘스트를 진행하던 중 사이드 퀘스트를 수행한 후 메인 퀘스트를 마저 수행해야 합니다.
그러면 사이드 퀘스트를 수행하러 가면 메인 퀘스트의 진행 상황, 맥락 등을 저장해야 할 겁니다.
이러한 구조가 후입선출, 스택과 같은 데이터 구조가 처리하기 좋은 구조입니다.
어느 명령어 주소에서 jump해서 왔는지, 어느 매개변수로 함수를 호출했는지, 레지스터 초기값이 어땠는지 등을 담고 있는곳이 스택 프레임이며, 스택 프레임을 저장하는 곳이 바로 스택입니다.
항상 함수 내의 지역변수만 사용할 수는 없을겁니다. 특정 데이터를 여러 함수에 걸처 사용해야 한다면. 프로그래머가 직접 제어할 수 있는 큰 메모리 영역이 필요하다면 heap을 사용할 수 있습니다.
보통 malloc 이나 new 예약어로 수행할 수 있습니다.
해당 명령어가 수행이 되면 표준 라이브러리의 구현에 따라서 systemcall을 호출하며, 커널 모드로 cpu가 바뀌며 커널 영역에서 코드가 실행됩니다.
메모리풀
사실 malloc을 이용해서 메모리를 요청하는것은 매우 복잡하며 시스템 성능에 영향을 미칩니다.
그래서, 메모리풀이라는 기능이 등장하게 되었는데 메모리풀은 응용프로그램 내에서 구현한 메모리 할당 전략 중 하나입니다.
특정 상황에서만 사용할 수 있다는 단점이 있지만, 사용패턴에 맞춰서 프로그래머가 직접 메모리를 할당해 놓고 사용할 수 있다는 장점이 있습니다.
스레드 전용 저장소를 사용하면 메모리 풀 사용 시나리오에서 스레드 안전도 달성할 수 있습니다.
4장. CPU
현대의 cpu에는 정말 여러가지 기능들이 한 패키지 안에 묶여있습니다.
캐시, 내장 그래픽, 인코더 등등.. 하지만 cpu의 본질적인 모습은 트랜지스터의 모음집이라고 생각합니다.
AND게이트, OR게이트, NOT게이트 3개의 게이트만으로 현재의 컴퓨터를 만들었다는게 처음에는 이해가 안됐었습니다.
하지만 컴퓨터 구조 수업도 듣고, Turing Complete라는 게임을 해 보면서 어떻게 해서 컴퓨터가 만들어졌는지를 약간이나마 이해해나갈 수 있었습니다.
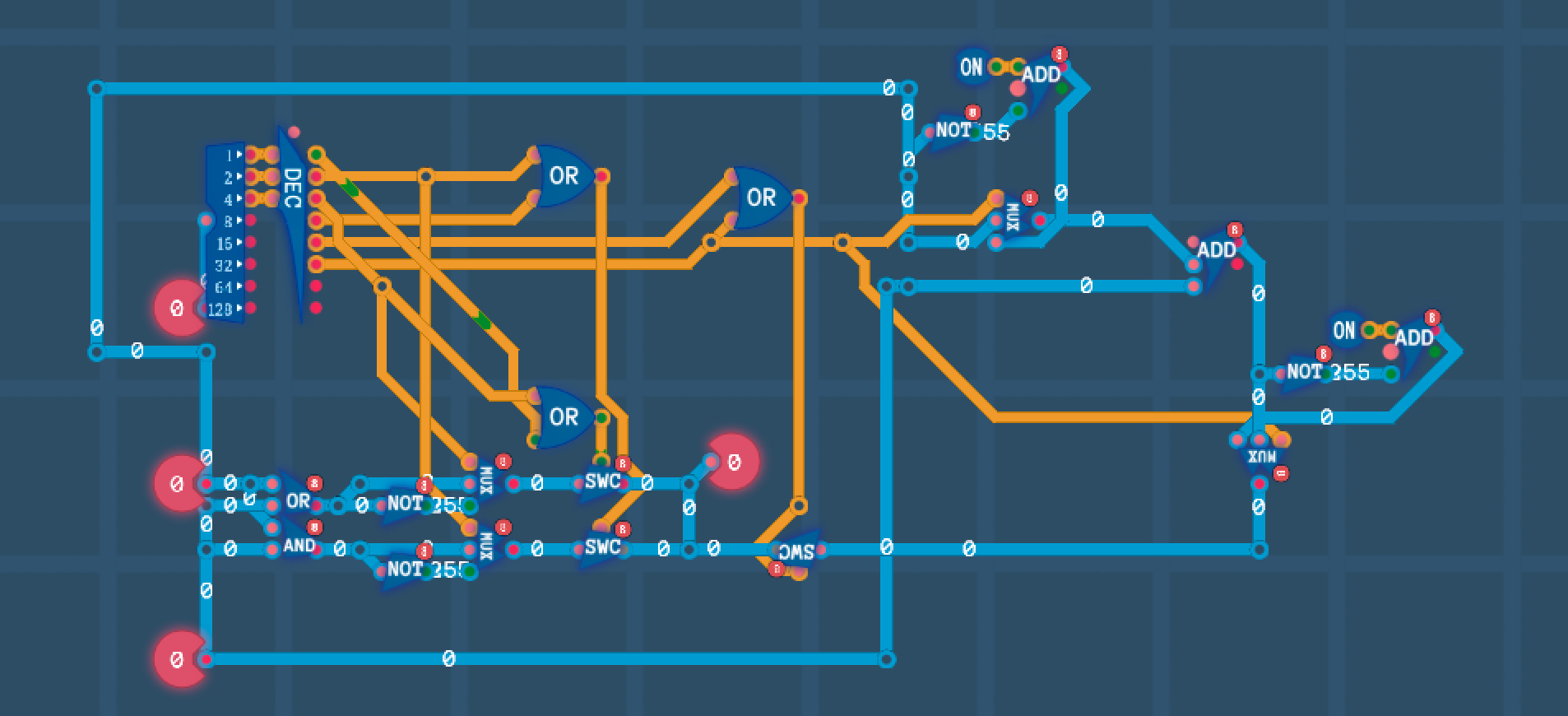
해당 게임내에서 AND, OR게이트등을 이용해서 ALU도 구현 해 보고..
(Switch, Decoder, Mux도 하위 단계에서 직접 만들어서 구현했었습니다)
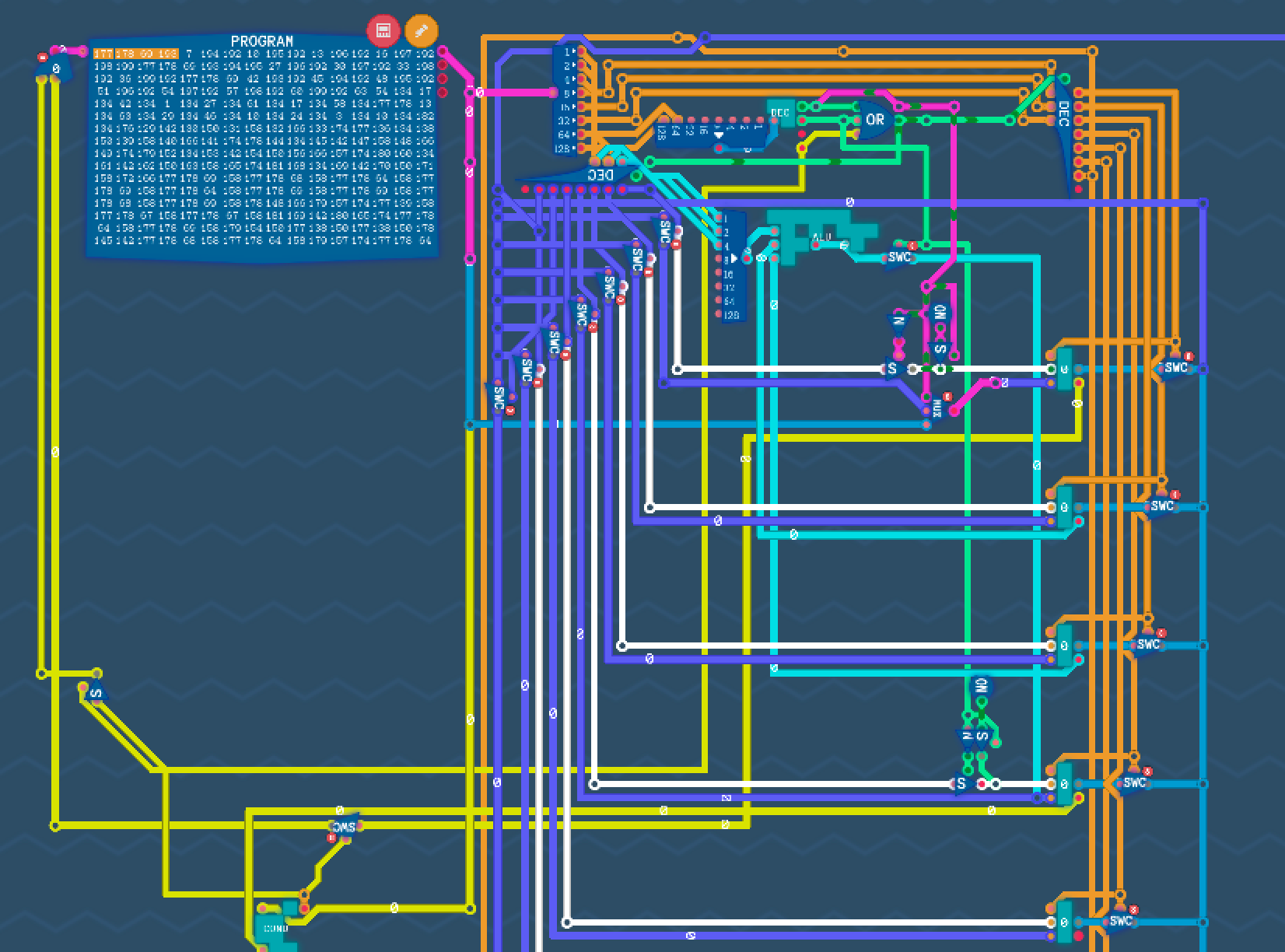
직접 구현 한 ALU와 Register들을 이용해서 작동하는 컴퓨터(?)를 만들어보기도 했습니다.
Ps. 위 게임은 오타쿠 같아보이지만 생각보다 더 재밌습니다. 약간 퍼즐같은 느낌?
아무튼, 이런 간단한 논리 게이트들을 이용해서 cpu를 구성하고,
사전에 정의한 ISA를 기반으로 해서 논리들을 하드웨어로 연산하거나 구현할 수 있습니다.
기존에 몰랐던 부분은 idle일때의 cpu를 잘 모르고 있었는데, halt라는 명령어를 사용할 때 일부 모듈을 절전 상태로 전환한다는 것을 새롭게 알게 되었습니다.
2진수
책에서는 2진수에 대한 내용도 다루는데, 아라비아 수 체계와 로마 수 체계의 비유에서부터 시작해서, 1의 보수, 2의 보수가 등장하게 된 배경도 설명 해 주니 이해가 한결 편했습니다.
파이프라이닝
파이프 라이닝은 하나의 명령어 실행을 여러개의 단계로 쪼개서 수행하는 방식입니다.
하나의 명령어 수행에 한 사이클이 돌게 설정을 하게 된다면 가장 긴 명령어의 실행시간에 비례하게 사이클을 조정할 수 밖에 없을 겁니다.
한편, 긴 명령어는 여러 사이클에 걸쳐서, 짧은 명령어는 그보단 적은 사이클에 걸쳐서 처리하고 한 사이클에 여러개의 명령어를 처리하는 방식을 채택하여 throughput을 높이려고 택한 방식이 pipelining입니다.
파이프라이닝을 택하면서 branch를 할때 분기 예측도 중요해졌는데, 컴퓨터 구조를 가르쳐주셨던 정성우 교수님께서 삼성에서 일하셨을 때 분기 예측쪽을 맡아서 해주셨다면서 말씀을 쭉 해주셨던 내용이 특히 기억에 남았었습니다.
RISC, CISC
파이프라이닝에 더해서 나왔던 내용이 RISC와 CISC였는데, 각각
Reduced Instruction Set Computer와 Complex Instruction Set Computer입니다.
처음 컴퓨터 구조 수업을 들었을때에는 RISC와 CISC가 정확히 어떤 차이가 있는지,
역사가 어떻게 되는지는 잘 모르고 있는 상태였는데, 책을 읽어가며 역사도 알아갈 수 있던 부분이 좋았습니다.
x86기반 프로세서보다 arm프로세서가 전성비나 성능이 우월하다 등..
얘기를 많이 들었었고, 현재 사용하고 있는 노트북도 arm기반의 mac을 쓰면서도 이 프로세서가 RISC기반이었다는 사실을 몰랐다는 점이 반성이 되었습니다.
Register와 Context
갑자기 RISC와 CISC 얘기를 하다가 register 내용이 왜 나오나 싶었는데,
cpu와 커널의 핵심적인 구성 요소인 syscall과 context(task_struct)등을 결국에 얘기를 하고 싶은 것이었습니다.
register는 보통 사용하는 메인 메모리(dram)과는 다른 sram으로 구성되어 있는데
클럭에 동기화되어 계산 결과를 저장하거나, pc를 저장하거나, 스택 포인터를 저장하거나.. 등등 명령어를 수행하는데 핵심적인 역할을 합니다.
사실 명령어의 계산도 레지스터를 이용해서 하니.. 없으면 cpu가 아니라고 할 수있겠죠.
이런식으로 레지스터는 특정 값을 저장하게 되는데, 이 값은 이전 명령어의 결과/현재 명령어의 중간과정/앞으로 실행할 명령어에 필요한/다음 명령어가 어떤것인지 등 특정한 맥락을 가지고 있기 때문에 한 실행 흐름에서 다른 실행흐름을 실행하기 위해선 이러한 맥락을 저장 할 필요가 있어집니다.
이때 이 맥락을 context라고 하고 register의 값을 포함해서 실행 흐름에 필요한 여러가지 요소들을 담고있는 구조체를 task_struct라고 합니다.